新翼博客 记录学习点滴
推荐系统中所使用的混合技术介绍
Posted by winares at 2013-12-02 with tags 推荐
在推荐系统实际运用中,各种混合技术是其中一项极为重要的核心技术。在工程实践中我们发现,混合技术对提升推荐效果、改进推荐系统的性能等都有重要意义,因此本文对该专题进行如下的一些总结和介绍。
引言
在这个信息爆炸的时代,消费者面临众多选择、未知的领域、过载的信息时,往往无所适从;然而与此同时,内容的生产者(例如商家)也在苦苦寻觅合适的用户,寻找最便捷的渠道,而解决这两类矛盾的最好工具就是推荐系统。
推荐系统缘起于搜索系统,在底层系统上两者有大量相通的技术,但是在相应用户需求和产生应用的场景上,推荐系统离用户更进一步:当用户的需求具体而明确时,他搜索;但当用户需求不明确或难以表达时,他需要推荐。另一方面,当用户需要找某个领域下公认的、热门的内容时,他搜索;但当用户需要找个性化的内容时,他需要推荐。很多场景下,用户的个性化需求是很难转化为简短明确的查询词的,例如“今天中午想找个附近的、符合我口味的、消费不贵的餐馆”这样的需求,非常常见但很难用查询词来表达清楚。推荐系统恰好可以填补这个空白,根据挖掘用户历史行为来将个性化的需求深入挖掘清楚,实现用武之地。
目前在电商、视频、文学、社交网络等等各类网站或应用中,推荐系统都开始扮演起一个越来越重要的角色。但是无论应用于什么系统,归根结底最关键的是必须保证高质量的推荐效果。
撇开产品、交互设计、基础数据等方面,如果从系统和算法的角度来看,混合推荐的思路是其中最为重要的部分。毫不夸张的说,在真实世界的应用中,无论产品规模的大或小、用户的多与少,只要是想要追求推荐效果的高水准,那么混合推荐一定是必不可少的一门绝技。原因为何?——下面来作个解释
为什么要有混合技术
推荐技术发展至今已经历了十余年,这期间众多的算法被提出并在业界运用,经过大量的实践,人们发现似乎没有任何一个方法可以独领风骚、包打天下,每种推荐方法都有其局限性,下面举些典型的例子说明:
基于物品的协同过滤(Item-based Collaborative Filtering)是推荐系统中知名度最高的方法,由亚马逊(Amazon)公司最早提出并在电商行业内被广泛使用。但基于物品的协同过滤在面对物品冷启动,以及数据稀疏的情况下效果急剧下降。同时基于物品的协同过滤倾向于推荐用户购买过商品的类似商品,往往会出现多样性不足、推荐惊喜度低的问题。
基于用户的协同过滤(User-based Collaborative Filtering)方法在推荐结果的新颖性方面有一定的优势,但是推荐结果的相关性较弱,且容易受潮流影响而倾向于推荐出大众性物品。同时新用户或低活跃用户也会遇到冷启动(Cold-Start)的棘手问题。
在多个推荐算法竞赛中,我们发现隐语义与矩阵分解模型(Latent Factor Model)及其各种改进升级方法(包括SVD++等)是推荐精度最好的单一模型方法,但当数据规模大时其运算性能会明显降低,同时基于MF的方法依赖全局进行计算信息,因而很难作增量更新,导致实际工程中会遇到不少困难。另外,隐语义模型还存在调整困难、可解释性差等问题。
基于内容的推荐算法(Content-based Recommendation)是最直观的推荐算法,这种方法实现简单,不存在冷启动问题,应对的场景丰富,属于“万金油”型打法。但在一些算法公开评测中,基于内容的方法效果都是垫底的之一。同时该算法依赖内容的描述程度,往往受限于对文本、图像或音视频内容进行分析的深度。
基于统计思想的一些方法,例如Slope One,关联规则(Association Rules),或者分类热门推荐等,计算速度快,但是对用户个性化偏好的描述能力弱,实际应用时也存在各种各样的问题,在此不多赘述。
怎样混合是个问题
解决各种推荐方法“硬伤”的一条最好的解决途径就是混合技术——它的思路非常明确,俗称“三个臭皮匠顶个诸葛亮”——即综合运用各种方法的优势、扬长避短,组合起来成为一个效果强大的系统。
道理虽然简单,但是怎样组合才能真正发挥威力?联想到一个有趣的电影片段:周星驰的喜剧电影《国产零零漆》中,神志不清的特工达文西“发明”了一个“要你命3000”的武器,这个“超级武器霸王”把一堆街头武器——“西瓜刀、铁链、火药、硫酸、毒药、手枪、手榴弹、杀虫剂”——用绳子绑在一起,但是完全没有作用,被对手一枪击毙。
在实际应用中,从系统、算法、结果、处理流程等不同的角度,都有一些具体的混合策略。下面依次从不同的角度来进行介绍。
多段组合混合推荐框架
推荐系统一方面要处理海量的用户、物品的数据,一方面要实时相应线上用户的请求,迅速的生成结果并返回。在这里存在一个矛盾是,离线数据挖掘(例如常见的Hadoop系统)虽然擅长处理大量数据,但运算周期长(小时级或天级)、实时推荐能力差,而在线系统由于要迅速(例如几十毫秒)计算出推荐结果,无法承担过于消耗资源的算法。
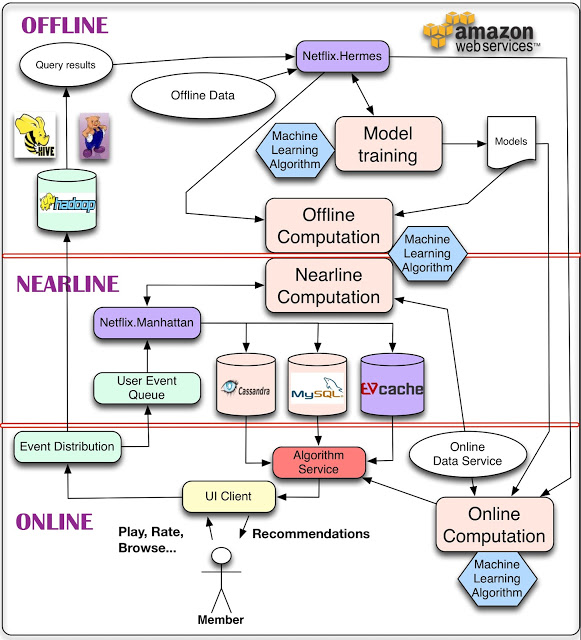
图1:Netflix的Online-Nearline-Offline混合推荐系统
在业界实际部署时,解决此类常见问题的流行方法是采用三段式混合系统:即Online-Nearline-Offline Recommendation(在线-近线-离线)三层混合机制。曾经举办过著名的国际推荐竞赛的Netflix公司,在所公开的后台推荐系统架构中,即采用了该混合系统(如图1)。
其中Online系统直接面向用户,是一个高性能和高可用性的推荐服务,在这里通常会设计有缓存(Cache)系统,来处理热门的请求(Query)重复计算的问题。而当Cache不命中的情况下,Online推荐运行一个运算简单可靠的算法,及时生成结果。Online系统后是Nearline系统,这个系统部署在服务端,一方面会接收Online系统发过来的请求,将Online计算的一些缓存结果,采用更复杂的算法重新计算并更新后更新缓存。另一方面Nearline是衔接Online和Offline系统的桥梁,因为Offline结果往往会挖掘长期的、海量的用户行为日志,消耗的资源大、挖掘周期长,但是Offline推荐系统计算所得的结果质量往往是最高的,这些结果会通过Nearline系统输送到线上,发挥作用。
另外一个不可忽视的问题是用户反馈的及时收集,并及时用于调整推荐结果。挖掘用户的反馈对调整推荐结果有莫大的帮助,但这个调整往往越及时越好,否则用户很容易对结果不满意而流失。这个点击挖掘和反馈的功能往往由Nearline推荐系统来承担,因为该系统收集前端反馈比较方便,又可以保证适当的处理时长。
加权型混合推荐技术
上面介绍了从系统架构的角度如何进行混合。而从算法的角度来看,则最常用的是采用加权型的混合推荐技术,即将来自不同推荐算法生成的候选结果及结果的分数,进一步进行组合(Ensemble)加权,生成最终的推荐排序结果。
具体来看,比较原始的加权型的方法是根据推荐效果,固定赋予各个子算法输出结果的权重,然后得到最终结果。很显然这种方法无法灵活处理不同的上下文场景,因为不同的算法的结果,可能在不同的场景下质量有高有低,固定加权系统无法各取所长。所以更好的思路是设置训练样本,然后比较用户对推荐结果的评价、与系统的预测是否相符,根据训练得到的结果生成加权的模型,动态的调整权重。
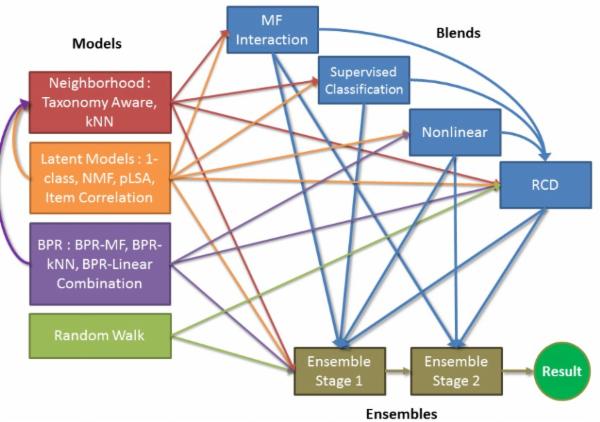
图2:加权混合技术能明显提高推荐精度
加权混合的模型有很多,除了简单的线性模型外,常用的有回归模型(Logistic Regression)、RBM(Restricted Boltzmann Machines)、GBDT(Gradient Boosted Decision Trees),这三种混合模型在推荐算法竞赛中大放异彩,在2009年结束的Netflix百万美元推荐竞赛中,优胜队伍将充分运用和多种加权混合模型的优势,组合后的算法推荐精度非常高。获胜队的Yehuda Koren在论文The BellKor Solution to the Netflix Grand Prize中对此有非常详细的介绍。另外值得一提的是台湾大学推荐团队,他们通过混合甚至二次混合的方式(如图2),将众多单独推荐算法的结果进行最合理的加权组合,在最近几届的KDD Cup数据挖掘竞赛中所向披靡,经常取得极为优异的推荐效果。
分级型混合推荐技术
尽管上述加权组合型混合推荐技术有非常高的精度,但系统复杂度和运算负载都较高。在工业界实际系统中,往往采用一些相对简单的方案,其中分级型混合推荐技术就是一类思想简单但效果也不错的方法。这种混合推荐技术根据不同的推荐场景,将不同的推荐算法按照效果优劣进行层次性划分。在对应的推荐场景下,优先采用高可信度的推荐算法生成的结果,然后依次采用后续方法生成结果。
在各种推荐场景中,Top-N推荐是最为常见的一类。这种推荐应用有时需要展示较多的推荐结果,而此时一种推荐算法的结果往往不够丰富,通常会采用分级型的混合技术,通过事先的数据挖掘,优先将推荐精度高的算法结果先列出,然后用依次用其他方法的结果递补。不同的推荐算法往往在精度(Precision)和召回(Recall)之间有所折衷,因此优先列出高精度结果,长尾部分则采用高召回的结果进行补足,能兼顾对推荐结果数量和质量的两种需求。
交叉调和技术
交叉调和技术有些类似西方酿造威士忌(Whisky)酒的过程——将纯麦威士忌、谷物威士忌、或者不同产地、口味的陈酿进行一定比例的调配后最终成品。交叉调和推荐技术(Blending Recommendation)的主要动机是保证最终推荐结果的多样性。因为不同用户对同一件物品的着眼点往往各不相同,而不同的推荐算法,生成的结果往往代表了一类不同的观察角度所生成的结果,交叉调和技术将不同推荐算法的生成结果,按照一定的配比组合在一起,打包后集中呈现给用户。
交叉调和技术需要注意的问题是结果组合时的冲突解决问题,通常会设置一些额外的约束条件来处理结果的组合展示问题。另外我们发现为了让用户更多的注意到结果的多样性,对不同类型的推荐结果辅以展示不同的推荐理由,往往能获得更多收益。
瀑布型混合方法
瀑布型(Waterfall Model)的混合方法采用了过滤(Filtering)的设计思想,将不同的推荐算法视为不同粒度的过滤器,尤其是面对待推荐对象(Item)和所需的推荐结果数量相差极为悬殊时,往往非常适用。
在瀑布型混合技术中,前一个推荐方法过滤的结果,将输出给后一个推荐方法,层层递进,候选结果在此过程中会被逐步遴选,最终得到一个高精确的结果。设计瀑布型混合系统中,通常会将运算速度快、区分度低的算法排在前列,逐步过渡为重量级的算法,这样的优点是充分运用不同算法的区分度,让宝贵的运算资源集中在少量较高候选结果的运算上。
推荐基础特征混合技术
数据是推荐系统的基础,一个完善的推荐系统,其数据来源也是多种多样的。从这些数据来源中我们可以抽取出不同的基础特征。以用户兴趣模型为例,我们既可以从用户的实际购买行为中,挖掘出用户的“显式”兴趣,又可以用用户的点击行为中,挖掘用户“隐式”兴趣;另外从用户分类、人口统计学分析中,也可以计算出用户兴趣;如果有用户的社交网络,那么也可以了解周围用户对该用户兴趣的投射,等等。另一方面,从物品(Item)的角度来看,也可以挖掘出不同的特征。
不同的基础特征可以预先进行组合或合并,为后续的推荐算法所使用。这样处理的优点是将推荐算法切分得比较清楚,这样将一个整体的推荐问题,分解为特征的抽取、组合、使用等各个环节的优化问题,在进行个性化推荐时较为适用。
推荐模型混合技术
和特征合并的技术不同,多模型的合并技术在模型计算阶段,将整个模型作为第二种算法的输入。这种组合方式,事实上形成了一种新的独立的推荐模型。例如在进行基于用户的协同过滤计算的时候,在计算相邻用户的距离的基础上,可以进一步根据用户的属性内容(Content)信息、采用基于内容的推荐的思想,进一步生成相似用户的候选结果;或者利用用户的社交网络信息(Social Network)来扩展相邻用户集合。这种在算法设计阶段而不是特征利用或推荐结果合并阶段的混合技术,被成为推荐模型混合技术。
这种技术往往适用于数据稀疏或质量较差时,单个推荐模型结果都比较差的情况。此时对多个较差的模型的最终结果进行合并无法获得满意的结果(因为候选结果都比较差),因此提前在模型计算阶段进行算法思路的合并,这样能提前召回好的结果,提升推荐效果。
整体式混合推荐框架
除了上述的系统架构、特征、算法、推荐结果等等角度的推荐融合技术,还有很多的内容是没有包括的,例如从商业逻辑的角度来分析,商家往往有一些特定的推荐需求或者推荐规则,需要对算法生成的结果进行调整。亦或者从交互设计的角度来看,推荐结果的展示方式等都有所不同;一些特殊的应用场景可能需要强调地域、时间等信息,对应的推荐挖掘方法和展现都有特殊的要求,这个时候对结果的混合往往要从整个产品的角度来进行设计和处理,从而能够满足不同的需要,这些可以被纳入整体式的混合推荐框架中考虑。
讨论和小结
推荐效果是一个推荐系统是否能获得成功的生命线,而混合推荐技术是其中最为重要的一个环节。在各种实际应用中,广大的研发工程师在处理很多问题时,往往都从直觉出发在不同程度的使用各种混合推荐技术,也解决了很多实际问题,取得了很好的效果。本文从理论角度对此进行了梳理,希望能帮助大家提升对推荐系统的领悟和理解。心中装着进行混合的意念,并理论联系实际,对开发一个成功的推荐系统会有莫大的帮助。
Markdown语法示例
Posted by winares at 2013-11-21 with tags Markdown
在搭建好blog之后,下一步就是写博文了,而要想方便的进行博客写作,那么Markdown是必不可少的工具。本文将通过一些简单的例子来说明Markdown的用法。
Markdown是一种轻量级标记语言,创始人为约翰·格鲁伯(John Gruber)和亚伦·斯沃茨(Aaron Swartz)。 它允许人们“使用易读易写的纯文本格式编写文档,然后转换成有效的XHTML(或者HTML)文档”。这种语言吸收了很多在电子邮件中已有的纯文本标记的特性。
宗旨
Markdown 的目标是实现「易读易写」。
可读性,无论如何,都是最重要的。一份使用 Markdown 格式撰写的文件应该可以直接以纯文本发布,并且看起来不会像是由许多标签或是格式指令所构成。Markdown 语法受到一些既有 text-to-HTML 格式的影响,包括 Setext、atx、Textile、reStructuredText、Grutatext 和 EtText,而最大灵感来源其实是纯文本电子邮件的格式。
总之, Markdown 的语法全由一些符号所组成,这些符号经过精挑细选,其作用一目了然。比如:在文字两旁加上星号,看起来就像强调。Markdown 的列表看起来,嗯,就是列表。Markdown 的区块引用看起来就真的像是引用一段文字,就像你曾在电子邮件中见过的那样。
标题
Markdown提供了两种方式(Setext和Atx)来显示标题。
语法:
Setext方式
标题1
=================
标题2
-----------------
Atx方式
# 标题1
## 标题2
###### 标题6
效果:
Setext方式
标题1
=================
标题2
Atx方式
# 标题1
## 标题2
###### 标题6
换行
在文字的末尾使用两个或两个以上的空格来表示换行。
引用
行首使用>加上一个空格表示引用段落,内部可以嵌套多个引用。
语法:
> 这是一个引用,
> 这里木有换行,
> 在这里换行了。
> > 内部嵌套
效果:
这是一个引用, 这里木有换行,
在这里换行了。 > 内部嵌套
列表
__无序列表__使用*、+或-后面加上空格来表示。
语法:
* Item 1
* Item 2
* Item 3
+ Item 1
+ Item 2
+ Item 3
- Item 1
- Item 2
- Item 3
效果:
- Item 1
- Item 2
-
Item 3
- Item 1
- Item 2
-
Item 3
- Item 1
- Item 2
- Item 3
__有序列表__使用数字加英文句号加空格表示。
语法:
1. Item 1
2. Item 2
3. Item 3
效果:
- Item 1
- Item 2
- Item 3
代码区域
__行内代码__使用反斜杠`表示。
__代码段落__则是在每行文字前加4个空格或者1个缩进符表示。
语法:
Bash中可以使用echo来进行输出。
$ echo 'Something'
$ echo -e '\tSomething\n'
效果:
Bash中可以使用echo来进行输出。
$ echo 'Something'
$ echo -e '\tSomething\n'
强调
Markdown使用\*或\_表示强调。
语法:
单星号 = *斜体*
单下划线 = _斜体_
双星号 = **加粗**
双下划线 = __加粗__
效果:
单星号 = 斜体
单下划线 = 斜体
双星号 = 加粗
双下划线 = 加粗
链接
Markdown支持两种风格的链接:Inline和Reference。
语法:
Inline:以中括号标记显示的链接文本,后面紧跟用小括号包围的链接。如果链接有title属性,则在链接中使用空格加“title属性”。
Reference:一般应用于多个不同位置使用相同链接。通常分为两个部分,调用部分为[链接文本][ref];定义部分可以出现在文本中的其他位置,格式为[ref]: http://some/link/address (可选的标题)。
注:ref中不区分大小写。
这是一个Inline[示例](http://winares.github.com "可选的title")。
这是一个Reference[示例][ref]。
[ref]: http://winares.github.com
效果:
这是一个Inline示例。
这是一个Reference[示例][ref]。
[ref]: http://winares.github.com
图片
图片的使用方法基本上和链接类似,只是在中括号前加叹号。
注:Markdown不能设置图片大小,如果必须设置则应使用HTML标记<img>。
语法:
Inline示例:
Reference示例:![替代文本][pic]
[pic]: /assets/images/ship.jpg "可选的title"
HTML示例:<img src="/assets/images/jian.jpg" alt="替代文本" title="标题文本" width="200" />
效果:

其他
自动链接
使用尖括号,可以为输入的URL或者邮箱自动创建链接。如test@domain.com。
分隔线
在一行中使用三个或三个以上的*、-或_可以添加分隔线,其中可以有空白,但是不能有其他字符。
转义字符
Markdown中的转义字符为\,可以转义的有:
- \\ 反斜杠
- \` 反引号
- \* 星号
- \_ 下划线
- \{\} 大括号
- \[\] 中括号
- \(\) 小括号
- \# 井号
- \+ 加号
- \- 减号
- \. 英文句号
- \! 感叹号
结语
Markdown语法很大程度上减少了编辑的成本,但是在写作这篇文章的时候也发现某些标记对中文的支持似乎并不完美,虽然这些缺陷可以通过直接插入HTML代码解决(但这么做一点都不漂亮)。总的来说,能够在离线状态下使用命令行模式进行写作还是很爽的,相比在线写作模式精力可以更专注。
git使用--SSH配置
Posted by winares at 2013-11-17 with tags git
First : 安装git,不多说
Next : 设置SSH Key
1. 检查是否已经有SSH Key。
如果说没有这个目录,就直接看第三步
2. 备份
3. 生成一个新的SSH
之后直接回车,不用填写东西。之后会让你输入密码。然后就生成一个目录.ssh ,里面有两个文件:id_rsa , id_rsa.pub
4. 把这个SSH放到github上。
先在GitHub上注册一个用户,然后进入account-setting ,把id_rsa.pub的内容复制进去就可以了。

然后把id_rsa.pub里的内容复制进去就可以了。

5. 测试
输入命令:
$ssh -T git@github.com
提示以下信息表示连接成功:
Hi user_name! You've successfully authenticated, but GitHub does not provide shell access.
Git基本操作
Posted by winares at 2013-11-16 with tags git
本文来自网络,仅作备忘之用。
git clone: 这是较为简单的一种初始化方式,当你已经有一个远程的Git版本库,只需要在本地克隆一份,例如’git clone git://github.com/someone/some_project.git some_project’命令就是将’git://github.com/someone/some_project.git’这个URL地址的远程版 本库完全克隆到本地some_project目录下面
git init和git remote:这种方式稍微复杂一些,当你本地创建了一个工作目录,你可以进入这个目录,使用’git init’命令进行初始化,Git以后就会对该目录下的文件进行版本控制,这时候如果你需要将它放到远程服务器上,可以在远程服务器上创建一个目录,并把 可访问的URL记录下来,此时你就可以利用’git remote add’命令来增加一个远程服务器端,例如’git remote add origin git://github.com/someone/another_project.git’这条命令就会增加URL地址为’git: //github.com/someone/another_project.git’,名称为origin的远程服务器,以后提交代码的时候只需要使用 origin别名即可
现在我们有了本地和远程的版本库,让我们来试着用用Git的基本命令吧:
git pull:从其他的版本库(既可以是远程的也可以是本地的)将代码更新到本地,例如:’git pull origin master’就是将origin这个版本库的代码更新到本地的master主枝,该功能类似于SVN的update
git add:是将当前更改或者新增的文件加入到Git的索引中,加入到Git的索引中就表示记入了版本历史中,这也是提交之前所需要执行的一步,例如’git add app/model/user.rb’就会增加app/model/user.rb文件到Git的索引中
git rm:从当前的工作空间中和索引中删除文件,例如’git rm app/model/user.rb’
git commit:提交当前工作空间的修改内容,类似于SVN的commit命令,例如’git commit -m “story #3, add user model”‘,提交的时候必须用-m来输入一条提交信息
git push:将本地commit的代码更新到远程版本库中,例如’git push origin’就会将本地的代码更新到名为orgin的远程版本库中
git log:查看历史日志
git revert:还原一个版本的修改,必须提供一个具体的Git版本号,例如’git revert bbaf6fb5060b4875b18ff9ff637ce118256d6f20’,Git的版本号都是生成的一个哈希值
上面的命令几乎都是每个版本控制工具所公有的,下面就开始尝试一下Git独有的一些命令:
git branch:对分支的增、删、查等操作,例如’git branch new_branch’会从当前的工作版本创建一个叫做new_branch的新分支,’git branch -D new_branch’就会强制删除叫做new_branch的分支,’git branch’就会列出本地所有的分支
git checkout:Git的checkout有两个作用,其一是在不同的branch之间进行切换,例如’git checkout new_branch’就会切换到new_branch的分支上去;另一个功能是还原代码的作用,例如’git checkout app/model/user.rb’就会将user.rb文件从上一个已提交的版本中更新回来,未提交的内容全部会回滚
git rebase:用下面两幅图解释会比较清楚一些,rebase命令执行后,实际上是将分支点从C移到了G,这样分支也就具有了从C到G的功能

git reset:将当前的工作目录完全回滚到指定的版本号,假设如下图,我们有A-G五次提交的版本,其中C的版本号是 bbaf6fb5060b4875b18ff9ff637ce118256d6f20,我们执行了’git reset bbaf6fb5060b4875b18ff9ff637ce118256d6f20’那么结果就只剩下了A-C三个提交的版本

git stash:将当前未提交的工作存入Git工作栈中,时机成熟的时候再应用回来,这里暂时提一下这个命令的用法,后面在技巧篇会重点讲解
git config:利用这个命令可以新增、更改Git的各种设置,例如’git config branch.master.remote origin’就将master的远程版本库设置为别名叫做origin版本库,后面在技巧篇会利用这个命令个性化设置你的Git,为你打造独一无二的 Git
git tag:可以将某个具体的版本打上一个标签,这样你就不需要记忆复杂的版本号哈希值了,例如你可以使用’git tag revert_version bbaf6fb5060b4875b18ff9ff637ce118256d6f20’来标记这个被你还原的版本,那么以后你想查看该版本时,就可以使用 revert_version标签名,而不是哈希值了
BLOG搭建手册
Posted by winares at 2013-11-15 with tags blog
这篇博文主要是总结自己在github上搭建blog的过程,因为在这其中还是有不少的心得和收获。 另外也是希望可以帮助那些想在github上建blog的同学少走一点弯路。
我想编过程序的人对github一定都或多或少有些了解。它号称程序员的Facebook,有着极高的人气,许多重要的项目都托管在上面。 但是对于一个新手来说,看到一大堆源码,只会让人头晕脑涨,不知何处入手。他希望看到的是,一个简明易懂的网页,说明每一步应该怎么做。 因此,github就设计了Pages功能,允许用户自定义项目首页,用来替代默认的源码列表。所以,github Pages可以被认为是用户编写的、托管在github上的静态网页,而我们所搭建的blog正是基于github pages的静态网页。 github提供模板,允许站内生成网页,但也允许用户自己编写网页,然后上传。有意思的是,这种上传并不是单纯的上传,而是会经过Jekyll程序的再处理。
Jekyll(”杰克尔”)是一个静态站点生成器,它会根据网页源码生成静态文件。它提供了模板、变量、插件等功能,所以实际上可以用来编写整个网站。 所以构建blog的思路到这里就很明显了。你先在本地编写符合Jekyll规范的网站源码,然后上传到github,由github生成并托管整个网站。
下面就要是介绍一下blog搭建的一些具体步骤,主要是一些命令行的操作,还是比较容易上手的。 如果你对ruby完全没有了解,仅仅对html有初步的了解,这都没有关系,只要你懂一点点linux命令就行, 例如ls,cd,mkdir,cp,ssh命令等(不懂也没有关系),不懂请用到时Google。一切软件的下载见后面的软件汇总,具体步骤如下:
安装ruby环境
因为Jekyll是利用Ruby实现的,因此我们需要涉及到一些关于Ruby的东西,可能你对Ruby不是很了解,但这没关系,因为我们只是简单的使用一下而已。 这里我们使用RailsInstaller,它提供了一种轻松便捷的方式来创建Ruby on Rails应用。 目前的RailsInstaller提供了如下功能: Rails、 Ruby、 SLQite、 Git、 DevKit。
安装RailInstaller,因为它集成了一系列的软件,因此使用起来也会比较方便,在安装过程中尽量使用默认的设置,这会为后面的工作节省很多精力。
配置Git
在RailInstaller安装完成界面(程序安装的最后一步),提示是否进行Git环境的配置,默认情况是选择是,选择“确定”就行。
如果你之前配置好了git,这边会自动检测到你的相关信息,如git帐号,邮箱,key,以及会显示一些软件信息如:ruby,git版本之类的, 并且自动cd到目录 /c/Sites下面,今后你只要将博客放在该目录下就行。 在开始菜单里找到RailsInstaller –> Git Bash,执行它,就打开了下面的命令窗口,以后的配置操作都是在这个窗口下进行的, 首先测试是否git可以正常连接,如果不能,请回到第一步进行Git的配置(该命令在运行,开始->程序->RailsInstaller –> Git Bash 控制台下执行(该控制台我主要是为配置环境用))。
ssh -T git@github.com 提示以下信息表示连接成功:
$ ssh -T git@github.com
Hi user_name! You've successfully authenticated, but GitHub does not provide shell
access.
安装Jekyll和相关包
首先更改一个镜像文件的地址:
gem sources --remove http://rubygems.org/
gem sources -a http://ruby.taobao.org/
然后用gem sources -l看看现在源列表
$ gem sources -l
*** CURRENT SOURCES ***
http://ruby.taobao.org/
http://ruby.taobao.org/
安装jekyll
gem install jekyll
建立github pages
在github.com上创建代码库,登录到自己的Github账户,选择New repository,比如新建一个名如:user_name.github.com的代码库, 然后在代码库页,选择右侧的下拉列表框:Settings,就会对该项目进行修改,找到Github Pages一栏,点击右侧Automatic Page Generator按钮,生成网页,稍等片刻系统就会将网页生成好。待生成好后,克隆自己的代码库
git clone git@github.com:user_name/user_name.github.com.git
执行以后,git会把存放在github上的代码库文件下载到本地的,生成名为user_name.github.com的目录。删掉.git目录,并且将网站文件放置在该文件夹下。
在这里你可以使用jekyll已有的模板,或者参考别人的模板进行编辑修改。
发布博文
打开Git Bash控制台,我们将在这儿继续博文的推送工作。 编辑博文,并以文件后缀.md命名,博文开头格式如下
---
layout: post
title: 编程心得
category: blog
description: blablaaaaaaaaaaa
---
正文。。。。。
文件命名方式如下: 2013-12-12-first-page.md 请确保你的文件被保存为不含 BOM 的 UTF-8(若不是将会出错,可以使用notepad++ 来进行格式转换) 使用git命令推送到git服务器上,先加入本地库中
git add .
git commit -m"new blog“
git push
如果你在其他机器上修改过,那么先要执行 git pull否则会提示: non-fast-forward错误
C:\Sites\username.github.com>git push
To git@github.com:username/username.github.com.git
! [rejected] master -> master (non-fast-forward)
error: failed to push some refs to 'git@github.com:username/username.github.com.git'
To prevent you from losing history, non-fast-forward updates were rejected
Merge the remote changes (e.g. 'git pull') before pushing again. See the
'Note about fast-forwards' section of 'git push --help' for details.
访问你的BLOG
等待一段时间,github就会为你生成网页。用浏览器打开网址:user_name.github.com,到此blog的搭建工作就算基本完成。
在整个过程中,要熟悉对git命令的使用,这其实是个基本功,熟能生巧。
软件汇总: - RailInstall下载链接:RailInstall-2.0.1