新翼博客 记录学习点滴
Larry Page密歇根大学毕业典礼演讲
Posted by winares at 2014-05-17 with tags 演讲
拉里·佩奇(Larry Page,1973.03.26-),全名劳伦斯·爱德华·佩奇(Lawrence Edward Page),Google搜索引擎的创始人之一,2011年4月4日佩奇正式出任谷歌CEO。佩奇为美国密歇根大学安娜堡分校的毕业生,拥有理工科学士学位;因其出色的领导才能获得过多项荣誉,以奖励他对工学院的贡献。他曾担任密西根大学Eta Kappa Nu荣誉学会的会长。其指导教授是Terry Winograd 博士。Google就是由Page在斯坦福大学发起的研究项目转变而来的。

09届的同学们!来点激情给我个回应。各位同学,我希望大家站起来向支持你们的亲朋好友挥手致意。你们一定能在人群中找到他们,借此机会表达你们的爱吧!能站在这里我感到非常荣幸。
等等,大家可能觉得有点矫情。“我很荣幸”这句话都说烂了。但真的是大实话,大家不知道:我对密歇根大学有特殊的感情。很久以前,1962年9月,天很冷,在密歇根大学里有一家餐厅,学生志愿者负责打扫厨房的天花板,大约十年才会打扫一次。
想象一下:有个叫格洛丽亚的女学生,爬上了高高的梯子,努力地打扫脏兮兮的天花板。而一个叫卡尔的寄宿生在下面偷窥,这是他俩的初次邂逅,他们就是我父母。所以说,我是地地道道从密歇根大学厨房里造出来的,我母亲今天也来了。我想找到当年那个厨房,在天花板挂个匾上刻”感谢父母”!
我的家人都毕业于密歇根大学:我哥、我父母、还有我。我爸在文凭数量上更胜一筹:他在这获得了三个半学位,其中一个是通信工程的博士。44年前,他们认为计算机火不了多久。为取得这个学位,爸妈做出了很大的牺牲。为了抚养刚出生的哥哥,省吃俭用。堂堂计算机博士,论文是我妈逐字敲出来的,讽刺吧?
我身上这套博士服是我爸的,还有这张毕业证,跟你们即将拿到手的一样,也是我爸的。还有我的内裤,呃……算了。我的祖父曾在雪佛兰汽车厂工作,他曾开车带两个孩子来到安娜堡。告诉他们:你们以后要上这所大学!听起来挺扯。不过两个孩子确实都进了密歇根大学,这就是我们家的“美国梦”。
我姑姑贝弗利今天也来了。爷爷以前经常扛着一个大铁锤,铁管上铸着大铅坨的那种。那是用来在静坐罢工时,保护自己的武器。小时候,我们常用它在后院打桩子。现在世道好了,大家不需要铁锤保护自己了。但以防万一,我还是把它带来了。后来我的父亲成为了一名教授,密歇根州立大学的教授,我很走运,因为教授的工作比较灵活,有大量的时间陪我。还有比这更棒的吗?
我想要告诉大家的是:这次回来,意义非凡!我不知道该如何表达我的喜悦之情。今天和家人还有你们相聚在此,我无比激动!因为这里造就了我,我为你们感到骄傲,也为你们的家人和朋友感到骄傲,因为我们都是密歇根大家庭的一员,它是我生命中不可或缺的一部分。同时,我也知道你们现在坐在台下的感受:听我们这些老家伙絮叨,老生常谈。别担心,我不是话痨。我给大家讲个追梦的故事,确切地说是一个将梦想变为现实的故事。
想想看:午夜你从美梦中醒来,然后躺下接着睡回笼觉,第二天早上准会把昨晚的美梦忘个精光。我23岁时,就做过这样的美梦。我猛然惊醒,想把所有的网络内容下载下来,通过链接的方式保存。于是,我抓起笔就开始写。还好我把握住机会,从梦里及时醒来,花了一整晚研究出实现方案,自信满满。
我对导师Terry Winograd说:下载整个网络需要几周时间。他点点头,其实心里清楚需要更久。但他很明智,没打击我。年轻人的激情不可小视!不过那时,创造一个搜索引擎,对我而言是天方夜谭。我从没动过这个念头。很久以后,我们偶然找到了更好的排序方式。做出了一级棒的搜索引擎,谷歌就这么诞生了。所以,当梦想闪现时,抓住它吧!我在这儿念书时,曾学过如何梦想成真。
听起来有点扯,但我确实从 “塑造领导力”夏令营中得到了启发。看,真的有人参加过的吧。我们的口号是“世上无难事只怕有心人“!我们被要求去实现自己看似疯狂的梦想。我想建立个人快速交通系统来替代公交,我知道你们还在研究。没准是今后解决交通问题的好方法。我时不时还在考虑交通问题,梦想不会消失,会变成习惯!我们现在花费精力做的事情,比如做饭、打扫、开车,今后占用的时间会越来越少,这不是天方夜谭。世上无难事,只怕有心人!
我认为,自古精英出狂人。这话听起来挺没溜,但正因为别人没你疯狂。你的对手就很少事实上,狂人屈指可数。碰巧我都认识,他们比狗仔队还忙,比亲戚还走得近,乐于接受一个又一个挑战。谷歌就有这样一帮人,我们的任务是整合全世界的信息,使其随手可得,随时可用。碉堡吧?但谷歌差一点夭折,因为我和我的搭档Sergey担心丢了博士学位。好在你们已经毕业。当时我们坚信自己是一只暴风雨里的小小鸟,总有一天会飞得很高。即使刷爆了三张信用卡,买来谷歌的第一批硬盘,也不曾后悔。
家长们,同学们。事实证明:多几张信用卡总是有用的,如果用一句话总结:如何改变世界。为了迷狂般的梦想而奋斗终生!其实在读博期间,我想参加三个项目。还好导师建议道:”为什么不先研究网络呢?”这个建议实在太好了,因为1995年网络就开始了迅猛发展。科技,尤其是网络确实能让人顺利变”懒”。你看三个人做的软件,能解决上百万人的需求问题,你让三个接线员回答上百万人的问题试试?只找到能撬起地球的杠杆,才能让人成功变懒。世界正在瞬息万变,但对你而言,这是个绝佳的时机!你可以不顾一切地追寻奇思,实现妙想,不要放弃梦想,世界需要你们!
我还想说个故事:如果某天你如现在这般欣喜若狂,就像从马戏团的炮口轰了出来,一头冲向蓝天。请铭记那一刻的美妙,同时请铭记那些和家人朋友共处的时光,铭记每一个上天赋予你改造世界的机遇,铭记为所爱的人做出的改变,铭记生活赋予的一切美好,但生活也能轻易将它夺走。人生无常,1996年3月下旬,我到斯坦福大学读研不久,我的父亲便因呼吸困难住进了医院。两个月以后,他去世了。我当时几乎崩溃,许多年后,我创业,恋爱。历生命的种种后,我总会想起我的父亲。我和Lucy去过一个偏远又炎热的村庄,在狭窄的街道上散步。
那里的人很友好,却极度贫穷。污水不经处理就径直流入饮水河道,我们遇到一个因小儿麻痹而瘸腿的小男孩。那是在印度村庄,少数还存在小儿麻痹症的地方。这种病主要归罪于污染的水源,我的父亲也有小儿麻痹症,他一年级去田纳西州旅行时患病,住院两个月后,由军用航班DC-3送回家,这是他第一次打飞的。
他在五年级的日记里写道:我必须在床上躺一年,不能上学。父亲一辈子呼吸困难,小儿麻痹症使他过早离开我们。现在即使有了疫苗,小儿麻痹症依然肆虐,在印度脚上的鞋子也会传播小儿麻痹症,穿过那被污染的携带着病毒的水沟,每走一步都在传播病毒,病毒横行于孩子们玩耍的每个角落,人类正在努力消灭小儿麻痹症。到目前为止,还有328例感染病例。让我们加速这一进程吧,也许你们中就有人能够实现这个目标。
我父亲曾作为学生代表在毕业典礼上致辞。我最近看到他的毕业演讲,震住了。他说,这是一个瞬息万变的时代,一个科学技术和人才就业在不断变革的时代,教育成为发展的必需品。我们有更多的时间做想做的事,因为工时减少,退休提前,我们期待这一刻的到来。参与或见证科学、医学、工业的飞速发展。人们说,一个国家的未来取决于对年轻人培养。
如果所有美国青年能像我们一样接受教育,美国的前景会更加光明;如果父亲还在世,他会为即将出世的小孙子而高兴,也我没获得博士学位而揪心。感谢密歇根大学!
他对于新事物总有着敏锐的观察,并充满热情。我时常幻想,他会如何看待现在的变化。如果他还在,这会是他人生中最美好的时光。他会像在糖果店的孩子那样开心,我们大部分人都很幸运,有家人为伴,有朋友相随,可能有些人正在憧憬和另一半的未来。当初家人带你来此读书,如今他们见证你毕业。
请务必珍惜!记住——他们才是你们生命中最重要的人!谢谢你妈妈!谢谢你 Lucy!谢谢大家!
深度学习概述:从感知机到深度网络
Posted by winares at 2014-05-10 with tags 深度学习
近些年来,人工智能领域又活跃起来,除了传统了学术圈外,Google、Microsoft、facebook等工业界优秀企业也纷纷成立相关研究团队,并取得了很多令人瞩目的成果。这要归功于社交网络用户产生的大量数据,这些数据大都是原始数据,需要被进一步分析处理;还要归功于廉价而又强大的计算资源的出现,比如GPGPU的快速发展。
除去这些因素,AI尤其是机器学习领域出现的一股新潮流很大程度上推动了这次复兴——深度学习。本文中我将介绍深度学习背后的关键概念及算法,从最简单的元素开始并以此为基础进行下一步构建。
(PS:本文译自一篇博客,作者行文较随意,但作者所介绍的知识还是非常好的,包括例子的选择、理论的介绍都很到位,由浅入深,本文作者也是Java deep learning library的作者,原文地址
机器学习基础
如果你不太熟悉相关知识,通常的机器学习过程如下:
1、机器学习算法需要输入少量标记好的样本,比如10张小狗的照片,其中1张标记为1(意为狗)其它的标记为0(意为不是狗)——本文主要使用监督式、二叉分类。
2、这些算法“学习”怎么样正确将狗的图片分类,然后再输入一个新的图片时,可以期望算法输出正确的图片标记(如输入一张小狗图片,输出1;否则输出0)。
这通常是难以置信的:你的数据可能是模糊的,标记也可能出错;或者你的数据是手写字母的图片,用其实际表示的字母来标记它。
感知机
感知机是最早的监督式训练算法,是神经网络构建的基础。
假如平面中存在 n 个点,并被分别标记为“0”和“1”。此时加入一个新的点,如果我们想知道这个点的标记是什么(和之前提到的小狗图片的辨别同理),我们要怎么做呢?
一种很简单的方法是查找离这个点最近的点是什么,然后返回和这个点一样的标记。而一种稍微“智能”的办法则是去找出平面上的一条线来将不同标记的数据点分开,并用这条线作为“分类器”来区分新数据点的标记。
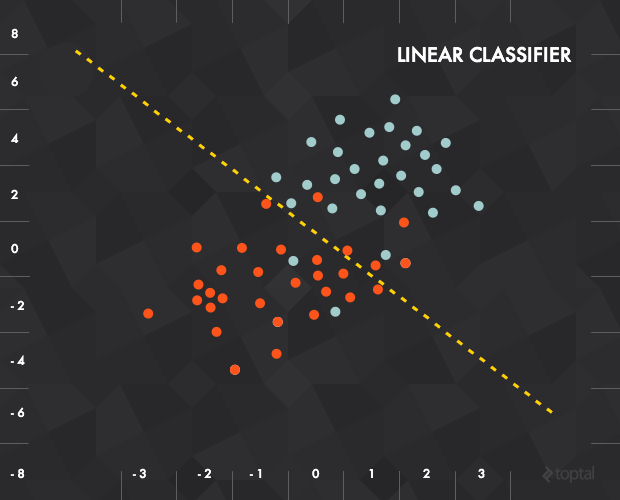
在本例中,每一个输入数据都可以表示为一个向量 x =(x_1,x_2) ,而我们的函数则是要实现“如果线以下,输出0;线以上,输出1”。
用数学方法表示,定义一个表示权重的向量 w 和一个垂直偏移量 b。然后,我们将输入、权重和偏移结合可以得到如下传递函数:
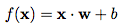
这个传递函数的结果将被输入到一个激活函数中以产生标记。在上面的例子中,我们的激活函数是一个门限截止函数(即大于某个阈值后输出1):
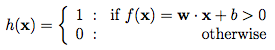
训练
感知机的训练包括多训练样本的输入及计算每个样本的输出。在每一次计算以后,权重 w 都要调整以最小化输出误差,这个误差由输入样本的标记值与实际计算得出值的差得出。还有其它的误差计算方法,如 均方差 等,但基本的原则是一样的。
缺陷
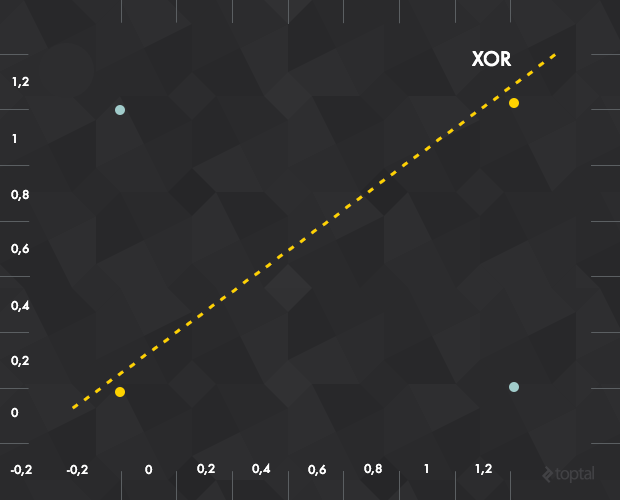
这种简单的感知机有一个明显缺陷:只能学习 线性可分函数 。这个缺陷重要吗?比如 XOR,这么简单的函数,都不能被线性分类器分类(如下图所示,分隔两类点失败):
为了解决这个问题,我们要使用一种多层感知机,也就是——前馈神经网络:事实上,我们将要组合一群这样的感知机来创建出一个更强大的学习机器。
前馈神经网络
神经网络实际上就是将大量之前讲到的感知机进行组合,用不同的方法进行连接并作用在不同的激活函数上。

我们简单介绍下前向神经网络,其具有以下属性:
*一个输入层,一个输出层,一个或多个隐含层。上图所示的神经网络中有一个三神经元的输入层、一个四神经元的隐含层、一个二神经元的输出层。 *每一个神经元都是一个上文提到的感知机。 *输入层的神经元作为隐含层的输入,同时隐含层的神经元也是输出层神经元的输入。 *每条建立在神经元之间的连接都有一个权重 w (与感知机中提到的权重类似)。 *在 t 层的每个神经元通常与前一层(t - 1层)中的每个神经元都有连接(但你可以通过将这条连接的权重设为0来断开这条连接)。 *为了处理输入数据,将输入向量赋到输入层中。在上例中,这个网络可以计算一个3维输入向量(由于只有3个输入层神经元)。假如输入向量是 [7, 1, 2],你将第一个输入神经元输入7,中间的输入1,第三个输入2。这些值将被传播到隐含层,通过加权传递函数传给每一个隐含层神经元(这就是前向传播),隐含层神经元再计算输出(激活函数)。 *输出层和隐含层一样进行计算,输出层的计算结果就是整个神经网络的输出。
超线性
如果每一个感知机都只能使用一个线性激活函数会怎么样?整个网络的最终输出也仍然是将输入数据通过一些线性函数计算过一遍,只是用一些在网络中收集的不同权值调整了一下。换名话说,再多线性函数的组合还是线性函数。如果我们限定只能使用线性激活函数的话,前馈神经网络其实比一个感知机强大不到哪里去,无论网络有多少层。
正是这个原因, 大多数神经网络都是使用的非线性激活函数,如对数函数、双曲正切函数、阶跃函数、整流函数等。不用这些非线性函数的神经网络只能学习输入数据的线性组合。
训练
大多数常见的应用在 多层感知机的监督式训练的算法都是反向传播算法。基本的流程如下:
1、将训练样本通过神经网络进行前向传播计算。
2、计算输出误差,常用均方差:
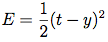
其中 t 是目标值,y 是实际的神经网络计算输出。其它的误差计算方法也可以,但MSE(均方差)通常是一种较好的选择。

3、网络误差通过 随机梯度下降 的方法来最小化。
梯度下降很常用,但在神经网络中,输入参数是一个训练误差的曲线。每个权重的最佳值应该是误差曲线中的全局最小值(上图中的 global minimum )。在训练过程中,权重以非常小的步幅改变(在每个样本或每小组样本训练完成后)以找到全局最小值,但这可不容易,训练通常会结束在局部最小值上(上图中的local minima)。如例子中的,如果当前权重值为0.6,那么要向0.4方向移动。
这个图表示的是最简单的情况,误差只依赖于单个参数。但是,网络误差依赖于每一个网络权重,误差函数非常、非常复杂。
好消息是反向传播算法提供了一种通过利用输出误差来修正两个神经元之间权重的方法。关系本身十分复杂,但对于一个给定结点的权重修正按如下方法(简单):
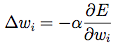
其中 E 是输出误差,w_i 是输入 i 的权重。
实质上这么做的目的是利用权重 i 来修正梯度的方向。关键的地方在于误差的导数的使用,这可不一定好计算:你怎么样能给一个大型网络中随机一个结点中的随机一个权重求导数呢?
答案是:通过反向传播。误差的首次计算很简单(只要对预期值和实际值做差即可),然后通过一种巧妙的方法反向传回网络,让我们有效的在训练过程中修正权重并 (期望) 达到一个最小值。
隐含层
隐含层十分有趣。根据 普适逼近原理 ,一个具有有限数目神经元的隐含层可以被训练成可逼近任意随机函数。换句话说,一层隐含层就强大到可以学习任何函数了。这说明我们在多隐含层(如深度网络)的实践中可以得到更好的结果。
隐含层存储了训练数据的内在抽象表示,和人类大脑(简化的类比)保存有对真实世界的抽象一样。接下来,我们将用各种方法来搞一下这个隐含层。
一个网络的例子
可以看一下这个通过 testMLPSigmoidBP 方法用Java实现的简单(4-2-3)前馈神经网络,它将 IRIS 数据集进行了分类。这个数据集中包含了三类鸢尾属植物,特征包括花萼长度,花瓣长度等等。每一类提供50个样本给这个神经网络训练。特征被赋给输入神经元,每一个输出神经元代表一类数据集(“1/0/0” 表示这个植物是Setosa,“0/1/0”表示 Versicolour,而“0/0/1”表示 Virginica)。分类的错误率是2/150(即每分类150个,错2个)。
大规模网络中的难题
神经网络中可以有多个隐含层:这样,在更高的隐含层里可以对其之前的隐含层构建新的抽象。而且像之前也提到的,这样可以更好的学习大规模网络。增加隐含层的层数通常会导致两个问题:
1、梯度消失:随着我们添加越来越多的隐含层,反向传播传递给较低层的信息会越来越少。实际上,由于信息向前反馈,不同层次间的梯度开始消失,对网络中权重的影响也会变小。
2、过度拟合:也许这是机器学习的核心难题。简要来说,过度拟合指的是对训练数据有着过于好的识别效果,这时导至模型非常复杂。这样的结果会导致对训练数据有非常好的识别较果,而对真实样本的识别效果非常差。
下面我们来看看一些深度学习的算法是如何面对这些难题的。
自编码器
大多数的机器学习入门课程都会让你放弃前馈神经网络。但是实际上这里面大有可为——请接着看。
自编码器就是一个典型的前馈神经网络,它的目标就是学习一种对数据集的压缩且分布式的表示方法(编码思想)。
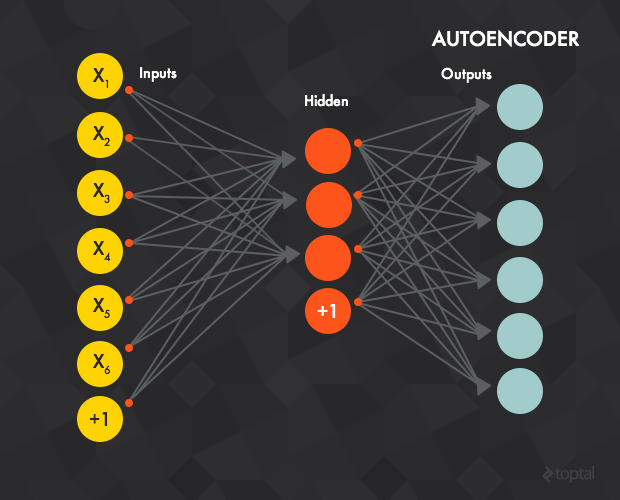
从概念上讲,神经网络的目的是要训练去“重新建立”输入数据,好像输入和目标输出数据是一样的。换句话说:你正在让神经网络的输出与输入是同一样东西,只是经过了压缩。这还是不好理解,先来看一个例子。
压缩输入数据:灰度图像
这里有一个由28x28像素的灰度图像组成的训练集,且每一个像素的值都作为一个输入层神经元的输入(这时输入层就会有784个神经元)。输出层神经元要有相同的数目(784),且每一个输出神经元的输出值和输入图像的对应像素灰度值相同。
在这样的算法架构背后,神经网络学习到的实际上并不是一个训练数据到标记的“映射”,而是去学习数据本身的内在结构和特征(也正是因为这,隐含层也被称作特征探测器(feature detector))。通常隐含层中的神经元数目要比输入/输入层的少,这是为了使神经网络只去学习最重要的特征并实现特征的降维。
我们想在中间层用很少的结点去在概念层上学习数据、产生一个紧致的表示方法。
流行感冒
为了更好的描述自编码器,再看一个应用。
这次我们使用一个简单的数据集,其中包括一些感冒的症状。如果感兴趣,这个例子的源码发布在这里
数据结构如下:
*输入数据一共六个二进制位 *前三位是病的证状。例如, 1 0 0 0 0 0 代表病人发烧; 0 1 0 0 0 0 代表咳嗽; 1 1 0 0 0 0 代表即咳嗽又发烧等等。 *后三位表示抵抗能力,如果一个病人有这个,代表他/她不太可能患此病。例如, 0 0 0 1 0 0 代表病人接种过流感疫苗。一个可能的组合是:0 1 0 1 0 0 ,这代表着一个接种过流感疫苗的咳嗽病人,等等。
当一个病人同时拥用前三位中的两位时,我们认为他生病了;如果至少拥用后三位中的两位,那么他是健康的,如:
*111000, 101000, 110000, 011000, 011100 = 生病 *000111, 001110, 000101, 000011, 000110 = 健康
我们来训练一个自编码器(使用反向传播),六个输入、六个输出神经元,而只有两个隐含神经元。
在经过几百次迭代以后,我们发现,每当一个“生病”的样本输入时,两个隐含层神经元中的一个(对于生病的样本总是这个)总是显示出更高的激活值。而如果输入一个“健康”样本时,另一个隐含层则会显示更高的激活值。
再看学习
本质上来说,这两个隐含神经元从数据集中学习到了流感症状的一种紧致表示方法。为了检验它是不是真的实现了学习,我们再看下过度拟合的问题。通过训练我们的神经网络学习到的是一个紧致的简单的,而不是一个高度复杂且对数据集过度拟合的表示方法。
某种程度上来讲,与其说在找一种简单的表示方法,我们更是在尝试从“感觉”上去学习数据。
受限波尔兹曼机
下一步来看下受限波尔兹曼机(Restricted Boltzmann machines RBM),一种可以在输入数据集上学习概率分布的生成随机神经网络。
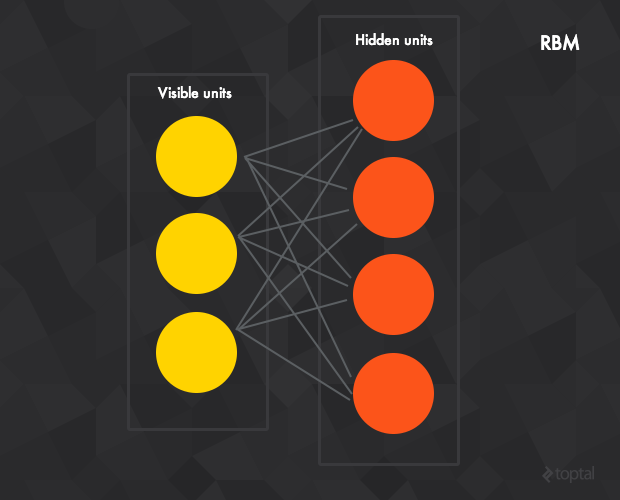
RBM由隐含层、可见层、偏置层组成。和前馈神经网络不同,可见层和隐含层之间的连接是无方向性(值可以从可见层->隐含层或隐含层->可见层任意传输)且全连接的(每一个当前层的神经元与下一层的每个神经元都有连接——如果允许任意层的任意神经元连接到任意层去,我们就得到了一个波尔兹曼机(非受限的))。
标准的RBM中,隐含和可见层的神经元都是二态的(即神经元的激活值只能是服从 伯努力分布 的0或1),不过也存在其它非线性的变种。
虽然学者们已经研究RBM很长时间了,最近出现的对比差异无监督训练算法使这个领域复兴。
对比差异
单步对比差异算法原理:
1、正向过程:
*输入样本 v 输入至输入层中。 *v通过一种与前馈网络相似的方法传播到隐含层中,隐含层的激活值为 h。 2、反向过程:
*将 h 传回可见层得到 v’(可见层和隐含层的连接是无方向的,可以这样传)。
*再将 v’ 传到隐含层中,得到 h’。
3、权重更新:
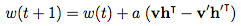
其中 a 是学习速率, v , v’ , h , h’ 和 w 都是向量。
算法的思想就是在正向过程中影响了网络的内部对于真实数据的表示。同时,反向过程中尝试通过这个被影响过的表示方法重建数据。主要目的是可以使生成的数据与原数据尽可能相似,这个差异影响了权重更新。
换句话说,这样的网络具有了感知对输入数据表示的程度的能力,而且尝试通过这个感知能力重建数据。如果重建出来的数据与原数据差异很大,那么进行调整并再次重建。
再看流行感冒的例子
为了说明对比差异,我们使用与上例相同的流感症状的数据集。测试网络是一个包含6个可见层神经元、2个隐含层神经元的RBM。我们用对比差异的方法对网络进行训练,将症状 v 赋到可见层中。在测试中,这些症状值被重新传到可见层;然后再被传到隐含层。隐含层的神经元表示健康/生病的状态,与自编码器相似。
在进行过几百次迭代后,我们得到了与自编码器相同的结果:输入一个生病样本,其中一个隐含层神经元具有更高激活值;输入健康的样本,则另一个神经元更兴奋。
例子的代码在 这里
深度网络
到现在为止,我们已经学习了隐含层中强大的特征探测器——自编码器和RBM,但现在还没有办法有效的去利用这些功能。实际上,上面所用到的这些数据集都是特定的。而我们要找到一些方法来间接的使用这些探测出的特征。
好消息是,已经发现这些结构可以通过栈式叠加来实现深度网络。这些网络可以通过贪心法的思想训练,每次训练一层,以克服之前提到在反向传播中梯度消失及过度拟合的问题。
这样的算法架构十分强大,可以产生很好的结果。如Google著名的 “猫”识别 ,在实验中通过使用特定的深度自编码器,在无标记的图片库中学习到人和猫脸的识别。
下面我们将更深入。
栈式自编码器
和名字一样,这种网络由多个栈式结合的自编码器组成。
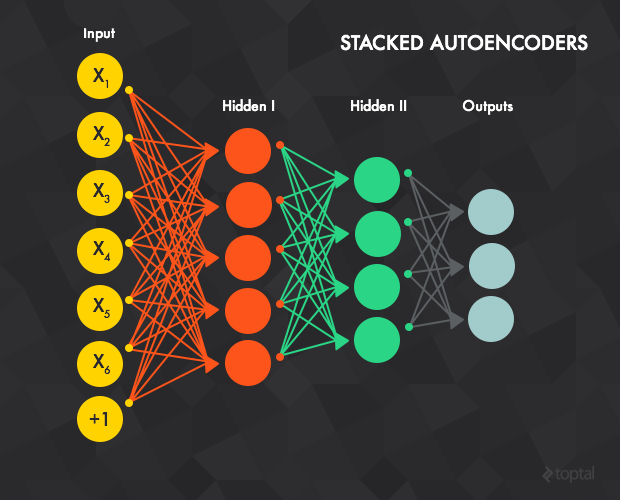
自编码器的隐含层 t会作为 t + 1 层的输入层。第一个输入层就是整个网络的输入层。利用贪心法训练每一层的步骤如下:
1、通过反向传播的方法利用所有数据对第一层的自编码器进行训练(t=1 ,上图中的红色连接部分)。
2、训练第二层的自编码器 t=2 (绿色连接部分)。由于 t=2 的输入层是 t=1 的隐含层,我们已经不再关心 t=1 的输入层,可以从整个网络中移除。整个训练开始于将输入样本数据赋到 t=1 的输入层,通过前向传播至t = 2的输出层。下面t = 2的权重(输入->隐含和隐含->输出)使用反向传播的方法进行更新。t = 2的层和 t=1 的层一样,都要通过所有样本的训练。
3、对所有层重复步骤1-2(即移除前面自编码器的输出层,用另一个自编码器替代,再用反向传播进行训练)。
4、步骤1-3被称为预训练,这将网络里的权重值初始化至一个合适的位置。但是通过这个训练并没有得到一个输入数据到输出标记的映射。例如,一个网络的目标是被训练用来识别手写数字,经过这样的训练后还不能将最后的特征探测器的输出(即隐含层中最后的自编码器)对应到图片的标记上去。这样,一个通常的办法是在网络的最后一层(即蓝色连接部分)后面再加一个或多个全连接层。整个网络可以被看作是一个多层的感机机,并使用反向传播的方法进行训练(这步也被称为微调)。
栈式自编码器,提供了一种有效的预训练方法来初始化网络的权重,这样你得到了一个可以用来训练的 复杂、多层的 感知机。
深度信度网络
和自编码器一样,我也可以将波尔兹曼机进行栈式叠加来构建深度信度网络(DBN)。
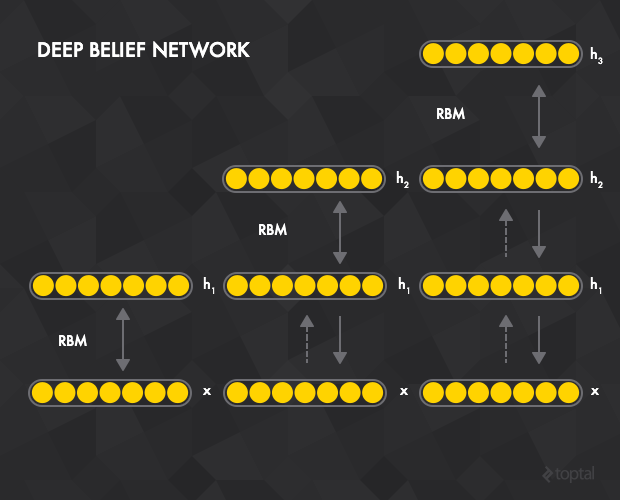
在本例中,隐含层 RBM t 可以看作是 RBM t+1 的可见层。第一个RBM的输入层即是整个网络的输入层,层间贪心式的预训练的工作模式如下:
-
通过对比差异法对所有训练样本训练第一个RBM t=1
-
训练第二个RBM t=1 。由于 t=2 的可见层是 t=1 的隐含层,训练开始于将数据赋至 t=1 的可见层,通过前向传播的方法传至 t=1 的隐含层。然后作为 t=2 的对比差异训练的初始数据。
-
对所有层重复前面的过程。
-
和栈式自编码器一样,通过预训练后,网络可以通过连接到一个或多个层间全连接的 RBM 隐含层进行扩展。这构成了一个可以通过反向传僠进行微调的多层感知机。
本过程和栈式自编码器很相似,只是用RBM将自编码器进行替换,并用对比差异算法将反向传播进行替换。
(注: 例中的源码可以从 此处 获得)
卷积网络
这个是本文最后一个软件架构——卷积网络,一类特殊的对图像识别非常有效的前馈网络。
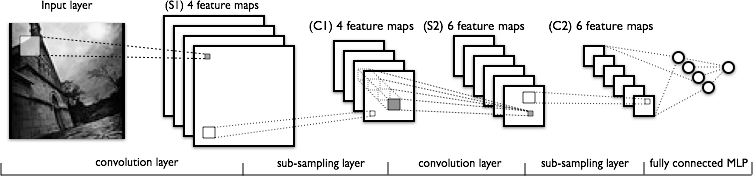
在我们深入看实际的卷积网络之臆,我们先定义一个图像滤波器,或者称为一个赋有相关权重的方阵。一个滤波器可以应用到整个图片上,通常可以应用多个滤波器。比如,你可以应用四个6x6的滤波器在一张图片上。然后,输出中坐标(1,1)的像素值就是输入图像左上角一个6x6区域的加权和,其它像素也是如此。
有了上面的基础,我们来介绍定义出卷积网络的属性:
*卷积层 对输入数据应用若干滤波器。比如图像的第一卷积层使用4个6x6滤波器。对图像应用一个滤波器之后的得到的结果被称为特征图谱(feature map, FM),特征图谱的数目和滤波器的数目相等。如果前驱层也是一个卷积层,那么滤波器应用在FM上,相当于输入一个FM,输出另外一个FM。从直觉上来讲,如果将一个权重分布到整个图像上后,那么这个特征就和位置无关了,同时多个滤波器可以分别探测出不同的特征。 *下采样层 缩减输入数据的规模。例如输入一个32x32的图像,并且通过一个2x2的下采样,那么可以得到一个16x16的输出图像,这意味着原图像上的四个像素合并成为输出图像中的一个像素。实现下采样的方法有很多种,最常见的是最大值合并、平均值合并以及随机合并。 *最后一个下采样层(或卷积层)通常连接到一个或多个全连层,全连层的输出就是最终的输出。 *训练过程通过改进的反向传播实现,将下采样层作为考虑的因素并基于所有值来更新卷积滤波器的权重。
可以在这看几个应用在 MNIST 数据集上的卷积网络的例子, 在这 还有一个用JavaScript实现的一个可视的类似网络。
实现
目前为止,我们已经学会了常见神经网络中最主要的元素了,但是我只写了很少的在实现过程中所遇到的挑战。
概括来讲,我的目标是实现一个 深度学习的库 ,即一个基于神经网络且满足如下条件的框架:
一个可以表示多种模型的通用架构(比如所有上文提到的神经网络中的元素) 可以使用多种训练算法(反向传播,对比差异等等)。 体面的性能 为了满足这些要求,我在软件的设计中使用了分层的思想。
结构
我们从如下的基础部分开始:
NeuralNetworkImpl 是所有神经网络模型实现的基类。 每个网络都包含有一个 layer 的集合。 每一层中有一个 connections 的链表, connection 指的是两个层之间的连接,将整个网络构成一个有向无环图。 这个结构对于经典的反馈网络、 RBM 及更复杂的如 ImageNet 都已经足够灵活。
这个结构也允许一个 layer 成为多个网络的元素。比如,在 Deep Belief Network (深度信度网络)中的layer也可以用在其 RBM 中。
另外,通过这个架构可以将DBN的预训练阶段显示为一个栈式RBM的列表,微调阶段显示为一个前馈网络,这些都非常直观而且程序实现的很好。
数据流
下个部分介绍网络中的数据流,一个两步过程:
定义出层间的序列。例如,为了得到一个多层感知机的结果,输入数据被赋到输入层(因此,这也是首先被计算的层),然后再将数据通过不同的方法流向输出层。为了在反向传播中更新权重,输出的误差通过广度优先的方法从输出层传回每一层。这部分通过 LayerOrderStrategy 进行实现,应用到了网络图结构的优势,使用了不同的图遍历方法。其中一些样例包含了 广度优先策略 和 定位到一个指定的层 。层的序列实际上由层间的连接进行决定,所以策略部分都是返回一个连接的有序列表。 计算激活值。每一层都有一个关联的 ConnectionCalculator ,包含有连接的列表(从上一步得来)和输入值(从其它层得到)并计算得到结果的激活值。例如,在一个简单的S形前馈网络中,隐含层的 ConnectionCalculator 接受输入层和偏置层的值(分别为输入值和一个值全为1的数组)和神经元之间的权重值(如果是全连接层,权重值实际上以一个矩阵的形式存储在一个 FullyConnected 结构中,计算加权和,然后将结果传给S函数。 ConnectionCalculator 中实现了一些转移函数(如加权求和、卷积)和激活函数(如对应多层感知机的对数函数和双曲正切函数,对应RBM的二态函数)。其中的大部分都可以通过 Aparapi 在GPU上进行计算,可以利用迷你批次训练。 通过 Aparapi 进行 GPU 计算
像我之前提到的,神经网络在近些年复兴的一个重要原因是其训练的方法可以高度并行化,允许我们通过GPGPU高效的加速训练。本文中,我选择 Aparapi 库来进行GPU的支持。
Aparapi 在连接计算上强加了一些重要的限制:
只允许使用原始数据类型的一维数组(变量)。 在GPU上运行的程序只能调用 Aparapi Kernel 类本身的成员函数。 这样,大部分的数据(权重、输入和输出数据)都要保存在 Matrix 实例里面,其内部是一个一维浮点数组。所有Aparapi 连接计算都是使用 AparapiWeightedSum (应用在全连接层和加权求和函数上)、 AparapiSubsampling2D (应用在下采样层)或 AparapiConv2D (应用在卷积层)。这些限制可以通过 Heterogeneous System Architecture 里介绍的内容解决一些。而且Aparapi 允许相同的代码运行在CPU和GPU上。
训练
training 的模块实现了多种训练算法。这个模块依赖于上文提到的两个模块。比如, BackPropagationTrainer (所有的训练算法都以 Trainer 为基类)在前馈阶段使用前馈层计算,在误差传播和权重更新时使用特殊的广度优先层计算。
我最新的工作是在Java8环境下开发,其它一些更新的功能可以在这个 branch 下获得,这部分的工作很快会merge到主干上。
结论
本文的目标是提供一个深度学习算法领域的一个简明介绍,由最基本的组成元素开始(感知机)并逐渐深入到多种当前流行且有效的架构上,比如受限波尔兹曼机。
神经网络的思想已经出现了很长时间,但是今天,你如果身处机器学习领域而不知道深度学习或其它相关知识是不应该的。不应该过度宣传,但不可否认随着GPGPU提供的计算能力、包括Geoffrey Hinton, Yoshua Bengio, Yann LeCun and Andrew Ng在内的研究学者们提出的高效算法,这个领域已经表现出了很大的希望。现在正是最佳的时间深入这些方面的学习。
附录:相关资源
如果你想更深入的学习,下面的这些资源在我的工作当中都起过重要的作用:
DeepLearning.net : 深度学习所有方面知识的一个门户。里面有完善的 手册 、 软件库 和一个非常好的 阅读列表 。 活跃的 Google+ 社区 . 两个很好的课程: Machine Learning and Neural Networks for Machine Learning , 都在Coursera上。 The Stanford neural networks tutorial ,斯坦福神经网络指南。
怎么培养数据分析的能力?
Posted by winares at 2014-04-21 with tags 数据分析
如果想深入学习数据分析的话建议了解一些数据挖掘的知识。
谈一些个人的工作经验,希望对后来人有帮助。首先总结下平时数据分析的一般步骤。
—————————浓缩精华版——————————–
第一步:数据准备:(70%时间)
获取数据(爬虫,数据仓库) 验证数据 数据清理(缺失值、孤立点、垃圾信息、规范化、重复记录、特殊值、合并数据集) 使用python进行文件读取csv或者txt便于操作数据文件(I/O和文件串的处理,逗号分隔) 抽样(大数据时。关键是随机) 存储和归档
第二步:数据观察(发现规律和隐藏的关联)
单一变量:点图、抖动图;直方图、核密度估计;累计分布函数 两个变量:散点图、LOESS平滑、残差分析、对数图、倾斜 多个变量:假色图、马赛克图、平行左边图
第三步:数据建模
推算和估算(均衡可行性和成本消耗) 缩放参数模型(缩放维度优化问题) 建立概率模型(二项、高斯、幂律、几何、泊松分布与已知模型对比)
第四步:数据挖掘
选择合适的机器学习算法(蒙特卡洛模拟,相似度计算,主成分分析) 大数据考虑用Map/Reduce 得出结论,绘制最后图表
循环到第二步到第四步,进行数据分析,根据图表得出结论完成文章。
——————————业务分析版——————————–
“无尺度网络模型”的作者艾伯特-拉斯洛·巴拉巴西认为——人类93%的行为是可以预测的。数据作为人类活动的痕迹,就像金矿等待发掘。但是首先你得明确自己的业务需求,数据才可能为你所用。
1.数据为王,业务是核心
了解整个产业链的结构 制定好业务的发展规划 衡量的核心指标有哪些
有了数据必须和业务结合才有效果。首先你需要摸清楚所在产业链的整个结构,对行业的上游和下游的经营情况有大致的了解。然后根据业务当前的需要,指定发展计划,从而归类出需要整理的数据。最后一步详细的列出数据核心指标(KPI),并且对几个核心指标进行更细致的拆解,当然具体结合你的业务属性来处理,找出那些对指标影响幅度较大的影响因子。前期资料的收集以及业务现况的全面掌握非常关键。
2.思考指标现状,发现多维规律
熟悉产品框架,全面定义每个指标的运营现状 对比同行业指标,挖掘隐藏的提升空间 拆解关键指标,合理设置运营方法来观察效果 争对核心用户,单独进行产品用研与需求挖掘
发现规律不一定需要很高深的编程方法,或者复杂的统计公式,更重要的是培养一种感觉和意识。不能用你的感觉去揣测用户的感觉,因为每个人的教育背景、生活环境都不一样。很多数据元素之间的关系没有明显的显示,需要使用直觉与观察(数据可视化技术来呈现)。
3.规律验证,经验总结
发现了规律之后不能立刻上线,需要在测试机上对模型进行验证。
P.S.数学建模能力对培养数感有一定的帮助
推荐两个论坛:
数学建模与数学应用论坛(Mathematical Modeling and Mathematical Applications Forum)
推荐系统知识点汇总
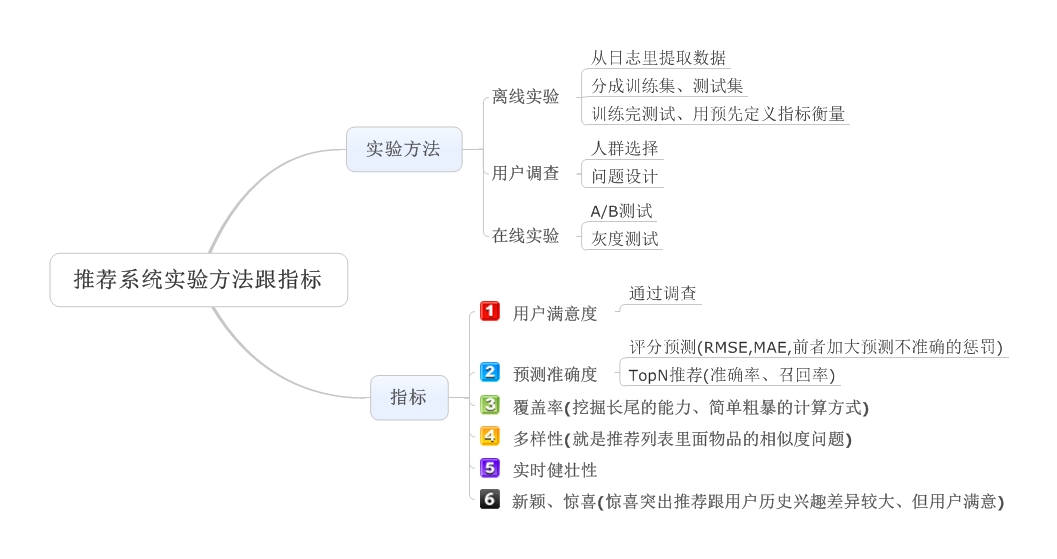
Posted by winares at 2014-03-14 with tags 推荐
主要是对《推荐系统实践》和《推荐系统导论》两本书的知识点的整理归纳。
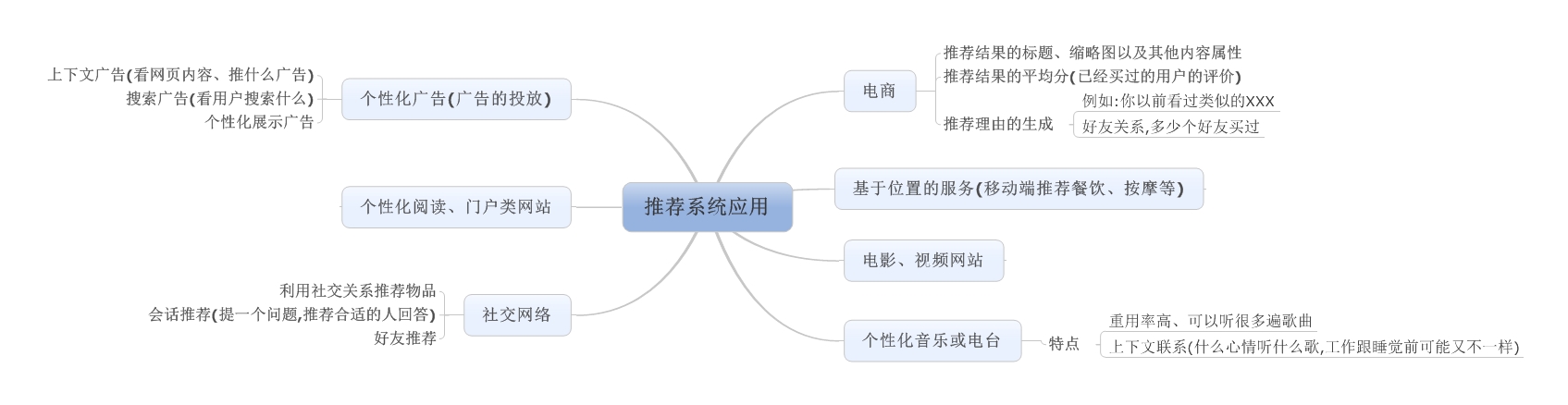
对推荐系统的建模数据进行分析,代表型数据:1)无上下文的隐形反馈数据;2) 无上下文的显性反馈数据;3) 有上下文的隐形反馈数据;4)有小上下文的显性反馈数据,其中显性的反馈数据就是用户对物品的评分,而隐形的就是用户对物品的浏览,时长等数据(不同的领域,用户对物品的行为种类不一样),像我之前的做的都全是用有上下文的隐形反馈,都是通过点击、登陆、时长归纳出来的用户对物品的评分。
有了用户数据以后,可以做一些行为的分析:1) 用户活跃度和物品流行度的分布(用户浏览过多少物品和物品被多少用户浏览过,符合长尾分布?);2) 用户活跃度跟物品流行度的关系(是不是新用户趋近于接触热门物品?);3) 用户的平均评分和物品的平均评分(流行度中等的物品的平均评分,可能平均分很高)
有了上面的数据跟分析之后,接下来就开始运用算法来建模了,常用的有基于领域的算法,基于隐语义模型,基于图模型等。
基于领域的算法
通常又分基于用户的和基于物品的CF,前一种算法的步骤:
(1)找到和目标用户兴趣相似的用户集合;
(2) 找到这个集合的用户喜欢听的,而且目标用户没有听过的物品
后一种算法的步骤:
(1)计算物品与物品之间的相似度;
(2) 通过目标用户已经正反馈的物品,来找到相似度其它物品。
上面2种算法的关键是找到用户/物品相似度集合,这里的用户/物品的相似度计算,不是用用户/物品的内在属性来衡量的(比如A物品是青苹果,B物品是红苹果,C物品是香蕉,用协同过滤的思想来计算的话,A跟B就不一定相似哦),直观上来讲 就是 如果A用户跟B用户 的物品重合性高,那么A跟B就相似,类似如果A物品跟B物品的共同用户重合性高,那么A跟B相似。
计算相似度的公式有很多种,余弦、皮尔逊、欧氏距离等。关于详细的公式请参考谷歌度娘。
实际应用需要注意的一些点:
1)余弦跟欧氏距离区别:我的感觉这两种方式,一个是定性,一个是定量,比如A用户对2个物品的评分是3,3,而B用户对这两个物品的评分是5,5,如果按余弦计算A,B就是相似的,而欧氏距离认为这两个用户还是有差异的;
2)通过余弦计算的时候,通常会做一个预处理,评分的用户会预先把每个物品的评分减去该用户的平均分 或者 加一个惩罚项(按物品的流行度/用户的活跃度)。计算用户跟用户相似度时 惩罚那些物品流行度高的,换句话说 2个用户对偏重冷门物品的有相同行为比对热门的有相同行为的更相似
3)对某用户活跃度太高的人,应该去除该用户
4) 相似度的归一化,提高推荐的多样性
user-cf的参数K值影响,K越大,结果越全局热门,覆盖面越小,流行度越大,通常运营与新闻类网站。

另外需要关注的就是哈利波特问题,就是某个物品太热了,而导致好多物品都会跟热门物品关联
最后,经常会问到的问题是:协同过滤跟关联规则有什么区别?
-
关联规则面向的是transaction,而协同过滤面向的是用户偏好(评分)。
-
协同过滤在计算相似商品的过程中可以使用关联规则分析,但是在有用户评分的情况下(非1/0),协同过滤算法应该比传统的关联规则更能产生精准的推荐。
-
协同过滤的约束条件没有关联规则强,或者说更为灵活,可以考虑更多的商业实施运算和特殊的商业规则。
基于隐语义模型
基于隐语义模型是近几年来研究比较火热的领域,特别是学术界,因为可以玩数学公式,出学术论文等。该模型的核心思想是通过隐变量(特征)来联系用户的兴趣跟物品。比较著名的方法有:PLSA,LDA,MF,LFM等,关于这些模型的目标损失函数,优化算法等请参考相应论文/技术博客
由于数据集里面的都是用户有正反馈行为的物品,那么如何采集用户的负样本呢?1) 对于每个用户,保证正负样本均衡;2) 采样负样本时,对更热门的负样本 加大采样权重。
案例:雅虎的新闻推荐,新闻在很短的时间内获得大量关注或是去关注,特别是刚出的新闻。这对于单纯的LFM很难实时推荐,因为需要在用户行为记录上反复迭代才能获取较好的性能。一个替代的方案是:预先利用新闻链接的内容属性(关键字、类别等)得到连接的内容特征向量跟用户对内容特征的兴趣程度(历史记录),然后再叠加最近几个小时更新的LFM,拿到用户实时的兴趣。最后通过两步叠加生成最后的实时结果
LMF跟基于领域的方法比较:
-
理论基础,前者有明确的优化函数,而基于领域的则更多的基于统计的方法,并没有一个学习的过程;
-
离线计算的空间复杂度:假设M个用户N个物品,对于LMF则需要O(F(M+N))的空间复杂度,F是隐变量的个数,对于user-cf需要O(MM)记录用户相关表,而item-cf要O(N*N)记录物品相关表
-
离线计算的时间复杂度:假设M个用户N个物品K条用户对物品的行为记录,对于LMF则需要O(FKS)的空间复杂度,F是隐变量的个数,S是迭代次数,对于user-cf需要O(M(K/M)^2)时间复杂度,而item-cf要O(M(K/M)^2) 时间复杂度
-
推荐解释,item-cf能给出很好的解释,而LFM则无法给出具体业务上的解释
基于图模型
由于用户物品的行为都可以转化为二分图的表示,那么就可以根据历史数据构建出这种形式,然后度量两个顶点之间的相似度的问题。基于这个思想的著名算法包括随机游走和PersonalRank算法。适合社交关系较强的数据应用上。
冷启动问题
常见的冷启动问题包括三类:1)用户冷启动(新用户没有历史行为,该怎么推荐?);2)物品冷启动(新物品,该如何向对齐感兴趣的用户推荐? item-cf受影响);3)系统冷启动(新开发的网站,没用户,只有一些物品信息,如何在网站发布的时候让访问的用户感受个性化推荐?)
对于上述的几个问题,可以参考几个常见的解决方案
-
对于新用户可以先进行热门推荐或热门物品的随机推荐,对于新物品可以考虑基于内容的推荐思想计算与其它物品的相似度;
-
利用用户注册信息,如年龄,性别,地区等(结合简单分析物品的用户年龄、性别、地区的分布,建立相关表),或者一开始让用户选一些自己感兴趣的tag,这样就可以进行粗粒度的个性化;
-
利用授权登陆获取到社交或其他信息,如淘宝跟新浪微博的相互打通;
-
系统冷启动时,可以引入专家(小编或运营人员等)建立起物品的相似表;
通常基于内容推荐通常是作为一个baseline,但是并不表示内容推荐就一定比基于领域的算法效果差,推荐系统实践一书举了个例子:如github的内容推荐就会相对比CF的要略好一点,因为用户的行为强烈的受到物品的某一属性影响,github浏览用户会受开源项目的作者影响,会关注这些知名作者的其他开源项目。
基于标签tag的推荐
最基本的统计用户常用的tag,然后统计被tag次数最多的哪些物品,最后找那些很热且含有用户常用tag的物品进行推荐
上面的问题:会给热门标签对于的热门物品很大的权重(用户常用的标签的热门物品),因此会造成推荐热门物品,降低新颖性。
改进1:类似的解决方法就是上面基于领域模型的惩罚热门标签(具体做法就是借鉴tf-idf思想记录常用标签被多少个其他用户使用过)跟热门物品
改进2:数据稀疏性的问题(再别的模型一样都会遇到的问题),把相似的tag聚类,例如某用户的tag是”推荐系统“,那么“个性化推荐”“协同过滤”tag应该也是用户会感兴趣的tag。放在别的算法可能就是对物品进行LDA聚类,抽象出来一类物品,稠密化数据。
上面讲的推荐模型里面的数据都是最基本的例如用户,物品,评分/tag,光有这些数据能产生推荐,但是推荐结果的质量就不一定了,有些时候从业务上看会很离谱(例如假设通过协同过滤算法得到一件外套跟t恤很相似,但是在夏天的时候,某一个用户买过T恤,难道要他推荐外套??)。所以除了上面讲的最基本的数据外,可以利用一些其他的信息来帮助改进推荐结果。这里统称为上下文信息(如时间,地点,情感心情等)
基于时间上下文的user-cf算法
算法的场景,例如A用户1个月前喜欢苹果,2个月前喜欢香蕉,B用户1个月前喜欢苹果,3个月前喜欢香蕉,而C用户跟A用户一样,1个月前喜欢苹果,2个月前喜欢香蕉,如果不加时间上下文关系,A、B、C用户的兴趣是相等的,但是加入时间上下文,那么A跟C 就会 比 B跟C 更相似;同理基于时间上下文的item-cf算法,也是采用了类似原理场景。实际操作的时候就是,对相似度计算公式的分子上面加一个兴趣相似的时间衰减函数,突出最近行为。
基于位置的推荐
给你推荐附近的酒店、餐馆等,移动时代这个显得更为重要,前段时间,百度公司出的春运,百度迁徙,火了互联网,就是因为掌握了用户的地理信息。再比如一个场景,淘宝的给用户推荐宝贝,是不是推荐也可以推荐一些离用户近的那些宝贝?还可以节省点路费,当然还需要其它因为,如成本,宝贝兴趣强弱关系等。
利用社交网络数据
用户社交关系数据对推荐的重要性不言而喻,更甚都可以不用复杂的推荐算法,单纯看社交关系进行推荐。如最近火的不行的”天天系列“,腾讯下面的游戏,基于微信平台,利用社交关系把用户粘的紧紧的,天然的满足用户的需求,即时不是玩游戏的用户。
社交数据的来源:电邮、用户注册(某个公司、某个学校、家乡等)、论坛/讨论组、即时聊天软件、社交网站等。
算法方面也是多种多样,基于图的社交挖掘(图是社交关系表达的最好表达方式)、基领域+社交关系的推荐、基于社交关系的矩阵分解等。
Git远程操作
Posted by winares at 2014-02-16 with tags git
Git是目前最流行的版本管理系统,学会Git几乎成了开发者的必备技能。
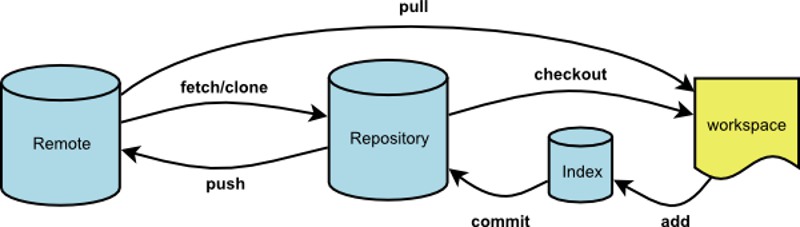
Git有很多优势,其中之一就是远程操作非常简便。本文详细介绍5个Git命令,它们的概念和用法,理解了这些内容,你就会完全掌握Git远程操作。
git clone git remote git fetch git pull git push
本文针对初级用户,从最简单的讲起,但是需要读者对Git的基本用法有所了解。同时,本文覆盖了上面5个命令的几乎所有的常用用法,所以对于熟练用户也有参考价值。
一、git clone
远程操作的第一步,通常是从远程主机克隆一个版本库,这时就要用到git clone命令。
$ git clone <版本库的网址> 比如,克隆jQuery的版本库。
$ git clone https://github.com/jquery/jquery.git 该命令会在本地主机生成一个目录,与远程主机的版本库同名。如果要指定不同的目录名,可以将目录名作为git clone命令的第二个参数。
$ git clone <版本库的网址> <本地目录名> git clone支持多种协议,除了HTTP(s)以外,还支持SSH、Git、本地文件协议等,下面是一些例子。
$ git clone http[s]://example.com/path/to/repo.git/ $ git clone ssh://example.com/path/to/repo.git/ $ git clone git://example.com/path/to/repo.git/ $ git clone /opt/git/project.git $ git clone file:///opt/git/project.git $ git clone ftp[s]://example.com/path/to/repo.git/ $ git clone rsync://example.com/path/to/repo.git/ SSH协议还有另一种写法。
$ git clone [user@]example.com:path/to/repo.git/ 通常来说,Git协议下载速度最快,SSH协议用于需要用户认证的场合。各种协议优劣的详细讨论请参考官方文档。
二、git remote
为了便于管理,Git要求每个远程主机都必须指定一个主机名。git remote命令就用于管理主机名。 不带选项的时候,git remote命令列出所有远程主机。
$ git remote origin 使用-v选项,可以参看远程主机的网址。
$ git remote -v origin git@github.com:jquery/jquery.git (fetch) origin git@github.com:jquery/jquery.git (push) 上面命令表示,当前只有一台远程主机,叫做origin,以及它的网址。 克隆版本库的时候,所使用的远程主机自动被Git命名为origin。如果想用其他的主机名,需要用git clone命令的-o选项指定。
$ git clone -o jQuery https://github.com/jquery/jquery.git $ git remote jQuery 上面命令表示,克隆的时候,指定远程主机叫做jQuery。 git remote show命令加上主机名,可以查看该主机的详细信息。
$ git remote show <主机名> git remote add命令用于添加远程主机。
$ git remote add <主机名> <网址> git remote rm命令用于删除远程主机。
$ git remote rm <主机名> git remote rename命令用于远程主机的改名。
$ git remote rename <原主机名> <新主机名>
三、git fetch
一旦远程主机的版本库有了更新(Git术语叫做commit),需要将这些更新取回本地,这时就要用到git fetch命令。
$ git fetch <远程主机名> 上面命令将某个远程主机的更新,全部取回本地。 默认情况下,git fetch取回所有分支(branch)的更新。如果只想取回特定分支的更新,可以指定分支名。
$ git fetch <远程主机名> <分支名> 比如,取回origin主机的master分支。
$ git fetch origin master 所取回的更新,在本地主机上要用”远程主机名/分支名”的形式读取。比如origin主机的master,就要用origin/master读取。 git branch命令的-r选项,可以用来查看远程分支,-a选项查看所有分支。
$ git branch -r origin/master
$ git branch -a * master remotes/origin/master 上面命令表示,本地主机的当前分支是master,远程分支是origin/master。 取回远程主机的更新以后,可以在它的基础上,使用git checkout命令创建一个新的分支。
$ git checkout -b newBrach origin/master 上面命令表示,在origin/master的基础上,创建一个新分支。 此外,也可以使用git merge命令或者git rebase命令,在本地分支上合并远程分支。
$ git merge origin/master # 或者 $ git rebase origin/master 上面命令表示在当前分支上,合并origin/master。
四、git pull
git pull命令的作用是,取回远程主机某个分支的更新,再与本地的指定分支合并。它的完整格式稍稍有点复杂。
$ git pull <远程主机名> <远程分支名>:<本地分支名> 比如,取回origin主机的next分支,与本地的master分支合并,需要写成下面这样。
$ git pull origin next:master 如果远程分支是与当前分支合并,则冒号后面的部分可以省略。
$ git pull origin next 上面命令表示,取回origin/next分支,再与当前分支合并。实质上,这等同于先做git fetch,再做git merge。
$ git fetch origin $ git merge origin/next 在某些场合,Git会自动在本地分支与远程分支之间,建立一种追踪关系(tracking)。比如,在git clone的时候,所有本地分支默认与远程主机的同名分支,建立追踪关系,也就是说,本地的master分支自动”追踪”origin/master分支。 Git也允许手动建立追踪关系。
git branch –set-upstream master origin/next 上面命令指定master分支追踪origin/next分支。 如果当前分支与远程分支存在追踪关系,git pull就可以省略远程分支名。
$ git pull origin 上面命令表示,本地的当前分支自动与对应的origin主机”追踪分支”(remote-tracking branch)进行合并。 如果当前分支只有一个追踪分支,连远程主机名都可以省略。
$ git pull 上面命令表示,当前分支自动与唯一一个追踪分支进行合并。 如果合并需要采用rebase模式,可以使用–rebase选项。
$ git pull –rebase <远程主机名> <远程分支名>:<本地分支名>
五、git push
git push命令用于将本地分支的更新,推送到远程主机。它的格式与git pull命令相仿。
$ git push <远程主机名> <本地分支名>:<远程分支名> 注意,分支推送顺序的写法是<来源地>:<目的地>,所以git pull是<远程分支>:<本地分支>,而git push是<本地分支>:<远程分支>。 如果省略远程分支名,则表示将本地分支推送与之存在"追踪关系"的远程分支(通常两者同名),如果该远程分支不存在,则会被新建。
$ git push origin master 上面命令表示,将本地的master分支推送到origin主机的master分支。如果后者不存在,则会被新建。 如果省略本地分支名,则表示删除指定的远程分支,因为这等同于推送一个空的本地分支到远程分支。
$ git push origin :master # 等同于 $ git push origin –delete master 上面命令表示删除origin主机的master分支。 如果当前分支与远程分支之间存在追踪关系,则本地分支和远程分支都可以省略。
$ git push origin 上面命令表示,将当前分支推送到origin主机的对应分支。 如果当前分支只有一个追踪分支,那么主机名都可以省略。
$ git push 如果当前分支与多个主机存在追踪关系,则可以使用-u选项指定一个默认主机,这样后面就可以不加任何参数使用git push。
$ git push -u origin master 上面命令将本地的master分支推送到origin主机,同时指定origin为默认主机,后面就可以不加任何参数使用git push了。 不带任何参数的git push,默认只推送当前分支,这叫做simple方式。此外,还有一种matching方式,会推送所有有对应的远程分支的本地分支。Git 2.0版本之前,默认采用matching方法,现在改为默认采用simple方式。如果要修改这个设置,可以采用git config命令。
$ git config –global push.default matching # 或者 $ git config –global push.default simple 还有一种情况,就是不管是否存在对应的远程分支,将本地的所有分支都推送到远程主机,这时需要使用–all选项。
$ git push –all origin 上面命令表示,将所有本地分支都推送到origin主机。 如果远程主机的版本比本地版本更新,推送时Git会报错,要求先在本地做git pull合并差异,然后再推送到远程主机。这时,如果你一定要推送,可以使用–force选项。
$ git push –force origin 上面命令使用–force选项,结果导致在远程主机产生一个”非直进式”的合并(non-fast-forward merge)。除非你很确定要这样做,否则应该尽量避免使用–force选项。 最后,git push不会推送标签(tag),除非使用–tags选项。
$ git push origin –tags
本文来自网络。
如何选择机器学习算法
Posted by winares at 2014-01-17 with tags 机器学习, 读书笔记
How do you know what machine learning algorithm to choose for your classification problem? Of course, if you really care about accuracy, your best bet is to test out a couple different ones (making sure to try different parameters within each algorithm as well), and select the best one by cross-validation. But if you’re simply looking for a “good enough” algorithm for your problem, or a place to start, here are some general guidelines I’ve found to work well over the years.
如何针对某个分类问题决定使用何种机器学习算法? 当然,如果你真心在乎准确率,最好的途径就是测试一大堆各式各样的算法(同时确保在每个算法上也测试不同的参数),最后选择在交叉验证中表现最好的。倘若你只是想针对你的问题寻找一个“足够好”的算法,或者一个起步点,这里给出了一些我觉得这些年用着还不错的常规指南。
How large is your training set?
训练集有多大?
If your training set is small, high bias/low variance classifiers (e.g., Naive Bayes) have an advantage over low bias/high variance classifiers (e.g., kNN), since the latter will overfit. But low bias/high variance classifiers start to win out as your training set grows (they have lower asymptotic error), since high bias classifiers aren’t powerful enough to provide accurate models.
如果是小训练集,高偏差/低方差的分类器(比如朴素贝叶斯)要比低偏差/高方差的分类器(比如k最近邻)具有优势,因为后者容易过拟合。然而随着训练集的增大,低偏差/高方差的分类器将开始具有优势(它们拥有更低的渐近误差),因为高偏差分类器对于提供准确模型不那么给力。
You can also think of this as a generative model vs. discriminative model distinction.
你也可以把这一点看作生成模型和判别模型的差别。
Advantages of some particular algorithms
一些常用算法的优缺点
Advantages of Naive Bayes: Super simple, you’re just doing a bunch of counts. If the NB conditional independence assumption actually holds, a Naive Bayes classifier will converge quicker than discriminative models like logistic regression, so you need less training data. And even if the NB assumption doesn’t hold, a NB classifier still often does a great job in practice. A good bet if want something fast and easy that performs pretty well. Its main disadvantage is that it can’t learn interactions between features (e.g., it can’t learn that although you love movies with Brad Pitt and Tom Cruise, you hate movies where they’re together).
朴素贝叶斯: 巨尼玛简单,你只要做些算术就好了。倘若条件独立性假设确实满足,朴素贝叶斯分类器将会比判别模型,譬如逻辑回归收敛得更快,因此你只需要更少的训练数据。就算该假设不成立,朴素贝叶斯分类器在实践中仍然有着不俗的表现。如果你需要的是快速简单并且表现出色,这将是个不错的选择。其主要缺点是它学习不了特征间的交互关系(比方说,它学习不了你虽然喜欢甄子丹和姜文的电影,却讨厌他们共同出演的电影《关云长》的情况)。
Advantages of Logistic Regression: Lots of ways to regularize your model, and you don’t have to worry as much about your features being correlated, like you do in Naive Bayes. You also have a nice probabilistic interpretation, unlike decision trees or SVMs, and you can easily update your model to take in new data (using an online gradient descent method), again unlike decision trees or SVMs. Use it if you want a probabilistic framework (e.g., to easily adjust classification thresholds, to say when you’re unsure, or to get confidence intervals) or if you expect to receive more training data in the future that you want to be able to quickly incorporate into your model.
逻辑回归: 有很多正则化模型的方法,而且你不必像在用朴素贝叶斯那样担心你的特征是否相关。与决策树与支持向量机相比,你还会得到一个不错的概率解释,你甚至可以轻松地利用新数据来更新模型(使用在线梯度下降算法)。如果你需要一个概率架构(比如简单地调节分类阈值,指明不确定性,或者是要得得置信区间),或者你以后想将更多的训练数据快速整合到模型中去,使用它吧。
Advantages of Decision Trees: Easy to interpret and explain (for some people – I’m not sure I fall into this camp). They easily handle feature interactions and they’re non-parametric, so you don’t have to worry about outliers or whether the data is linearly separable (e.g., decision trees easily take care of cases where you have class A at the low end of some feature x, class B in the mid-range of feature x, and A again at the high end). One disadvantage is that they don’t support online learning, so you have to rebuild your tree when new examples come on. Another disadvantage is that they easily overfit, but that’s where ensemble methods like random forests (or boosted trees) come in. Plus, random forests are often the winner for lots of problems in classification (usually slightly ahead of SVMs, I believe), they’re fast and scalable, and you don’t have to worry about tuning a bunch of parameters like you do with SVMs, so they seem to be quite popular these days.
决策树: 易于解释说明(对于某些人来说 —— 我不确定我是否在这其中)。它可以毫无压力地处理特征间的交互关系并且是非参数化的,因此你不必担心异常值或者数据是否线性可分(举个例子,决策树能轻松处理好类别A在某个特征维度x的末端,类别B在中间,然后类别A又出现在特征维度x前端的情况)。它的一个缺点就是不支持在线学习,于是在新样本到来后,决策树需要全部重建。另一个缺点是容易过拟合,但这也就是诸如随机森林(或提升树)之类的集成方法的切入点。另外,随机森林经常是很多分类问题的赢家(通常比支持向量机好上那么一点,我认为),它快速并且可调,同时你无须担心要像支持向量机那样调一大堆参数,所以最近它貌似相当受欢迎。
Advantages of SVMs: High accuracy, nice theoretical guarantees regarding overfitting, and with an appropriate kernel they can work well even if you’re data isn’t linearly separable in the base feature space. Especially popular in text classification problems where very high-dimensional spaces are the norm. Memory-intensive, hard to interpret, and kind of annoying to run and tune, though, so I think random forests are starting to steal the crown.
支持向量机: 高准确率,为避免过拟合提供了很好的理论保证,而且就算数据在原特征空间线性不可分,只要给个合适的核函数,它就能运行得很好。在动辄超高维的文本分类问题中特别受欢迎。可惜内存消耗大,难以解释,运行和调参也有些烦人,所以我认为随机森林要开始取而代之了。
But…
然而。。。
Recall, though, that better data often beats better algorithms, and designing good features goes a long way. And if you have a huge dataset, then whichever classification algorithm you use might not matter so much in terms of classification performance (so choose your algorithm based on speed or ease of use instead).
尽管如此,回想一下,好的数据却要优于好的算法,设计优良特征是大有裨益的。假如你有一个超大数据集,那么无论你使用哪种算法可能对分类性能都没太大影响(此时就根据速度和易用性来进行抉择)。
And to reiterate what I said above, if you really care about accuracy, you should definitely try a bunch of different classifiers and select the best one by cross-validation. Or, to take a lesson from the Netflix Prize (and Middle Earth), just use an ensemble method to choose them all.
再重申一次我上面说过的话,倘若你真心在乎准确率,你一定得尝试多种多样的分类器,并且通过交叉验证选择最优。要么就从Netflix Prize(和Middle Earth)取点经,用集成方法把它们合而用之,妥妥的。